Was Data in the TOGETHER Trial Fabricated?

This article is part of a series on the TOGETHER trial. More articles from this series here.
I might be wrong about this, but I can’t possibly see how. Perhaps someone can give me a hint about what I’m missing, because otherwise this is an obvious signature of data manipulation.
The Discrepancy
Let’s take it from the top: the fluvoxamine trial ran from Jan 20, 2021 to Aug 5, 2021 [1], while the ivermectin trial ran from Mar 23, 2021 to Aug 6, 2021 [2].
The ivermectin paper describes any other placebo patients as "nonconcurrent placebo," making it clear that while the ivermectin trial was running, no other placebo patients were being recruited.
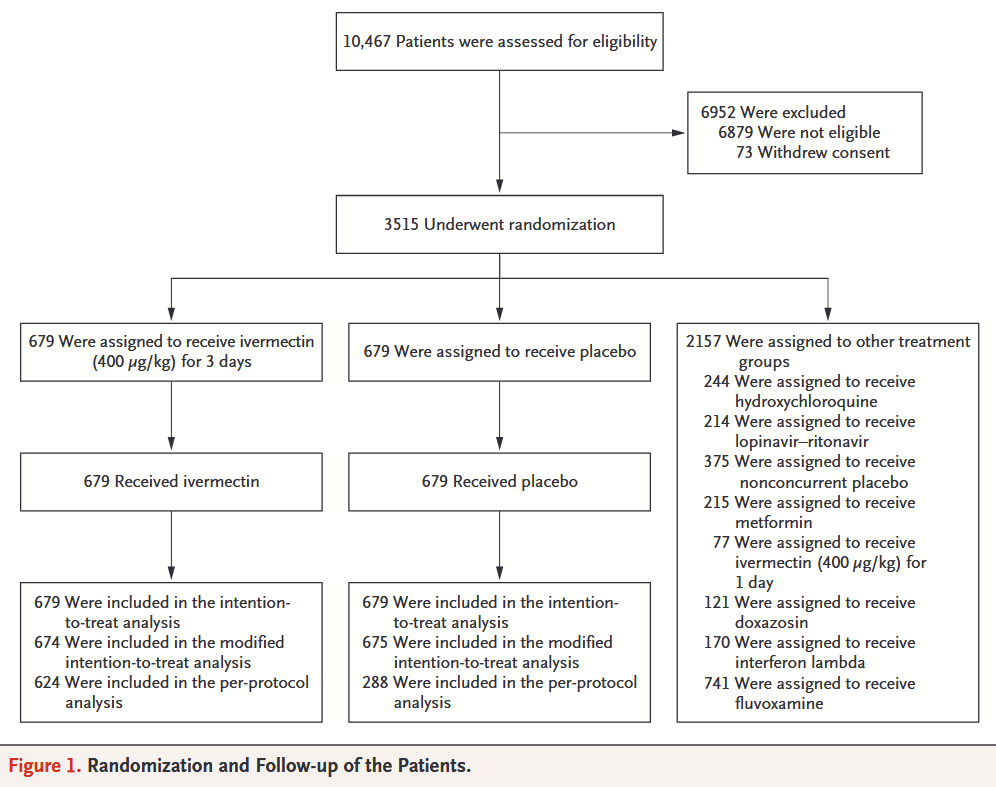
The fluvoxamine placebo arm reports 756 placebo patients[3], while the ivermectin placebo arm reports 679 [4].
Since the start date of the high-dose ivermectin trial is after the start date of the fluvoxamine trial, and the end date of the high-dose ivermectin trial is just one day after the end of the fluvoxamine trial, given that there were no other placebo patients recruited while the ivermectin arm was running, every placebo patient that was used in the ivermectin study must have been included in the fluvoxamine study placebo group also, except any small number of patients randomized exactly on Aug 6th. In fact, in slides released on Aug 6th, with a file timestamp of 5:38am, high-dose ivermectin placebo appears to include 678 patients, confirming that any recruitment that happened on Aug 6th was minimal.
The ivermectin paper reports in its placebo group as risk factors:
Chronic pulmonary disease (CPD): 23
Asthma: 60
Chronic kidney disease (CKD): 5
Chronic cardiac disease (CCD): 10
The fluvoxamine paper reports in its placebo group:
Chronic pulmonary disease: 3
Asthma: 16
Chronic kidney disease: 2
Chronic cardiac disease: 7
This looks like an excess of (23 - 3 =) 20 CPD patients, and (60 - 16 =) 44 asthma patients, (10 - 7 =) 3 CCD patients, and (5 - 2 =) 3 CKD patients. All these patients were somehow in the ivermectin placebo group, but not in the fluvoxamine placebo group. Either all of them were recruited exactly on August 6th, or I'm missing something big. On average, the TOGETHER trial randomized 3.4 patients to the placebo group per day in that period, so it is impossible for these numbers to be explained by a single day’s recruitment without something extremely irregular happening.
What About Multiple Imputation?
[UPDATE: this section is new as of the 9th of April 2021]
A response on Twitter has emerged, alleging that the critique in this article is invalid, given that Table 1 in the ivermectin paper has this footnote: “Missingness in covariate data was handled with multiple imputation by chained equations”.
This is an argument that I considered heading off in the initial version of this article, but chose to omit it due to the complexity that would be required in order to explain a fairly straightforward intuition: multiple imputation is not a magic wand that can be invoked to cure data inconsistencies of this magnitude. And in the unlikely case where it is actually the explanation for such unlikely inconsistencies, it is incumbent upon the authors to provide explanation to the readers. However, since the argument has been raised, I have added this section to explain why I don’t believe that the explanation works.
So what is multiple imputation by chained equations, also known as MICE? In simple terms, it is common for data from clinical studies to have gaps. The world of clinical trials is messy, and in many cases not all the desired data can be collected from all patients. MICE is a statistical approach to filling in those missing values, so that statistical analyses don’t lose the ability to utilize the entirety of the legitimately collected data.
The trial Statistical Analysis Plan specifies that MICE will be used for specific reason and within a specific constraint:

We have to assume the imputation used in Table 1 was within the mandate offered by the Statistical Analysis Plan. This means that at most 20% of values can be filled in with MICE.
So, in our case, focusing on the risk factors of asthma, the fluvoxamine paper notes that there are 16 patients with that particular risk factor in the placebo group. The ivermectin paper includes a control group that is a subset of that placebo group, so we should expect *at most* 16 cases of asthma in the ivermectin control group. We have 60 instead. So the hypothesis here is that the 44 additional cases come from filling in at most 20% missing values. You can see where this is going, but let’s make it a bit clearer.
Let’s see what it would mean for MICE to have been used on the risk factor values:
For simplicity, we will assume the maximum possible, 20% of values, are handled with MICE, and all the patients with a risk factor (e.g. Asthma cases) in the fluvoxamine placebo group are included within the subgroup that makes up the ivermectin placebo group. We would have:
Observed values: 80% of the placebo group (543 patients) includes 16 patients with asthma
Imputed values: 20% of the placebo group (136 patients) includes 44 patients with asthma
In other words, the imputed values would be 11 times more likely than the observed ones to indicate asthma as a risk factor.
In the case of CPD, things would be even more extreme:
Observed values: 80% of the placebo group (543 patients) includes 3 patients with CPD
Imputed values: 20% of the placebo group (136 patients) includes 20 patients with CPD
Thus, the imputed values would be 25 times more likely than the observed ones to indicate CPD as a risk factor.
For either of these multipliers to appear on their own, we would be looking at a highly unlikely outcome. For both of these multipliers to appear in the same paper, assuming this is an explanation that the authors endorsed, it would be incumbent upon them to provide a clear explanation for why their imputation algorithm completed this many missing values with such high prevalence of these specific risk factors.
There’s another important assumption required to apply MICE: it can only be used where the values that are missing are missing at random (either MAR or MCAR). In other words, the reason for the values missing cannot be the values themselves. If the reason for the gaps in the data is that e.g. asthma patients were less likely to answer the question *because* they are asthma patients, then MICE is an improper method to use to handle missing values.
In 2012, the members of an expert panel convened by the National Research Council published a set of recommendations in the New England Journal of Medicine, in a special report titled The Prevention and Treatment of Missing Data in Clinical Trials. In it, they say:
Substantial instances of missing data are a serious problem that undermines the scientific credibility of causal conclusions from clinical trials. The assumption that analysis methods can compensate for such missing data are not justified, so aspects of trial design that limit the likelihood of missing data should be an important objective.
As a last resort, when analysis methods must be used, they recommend:
sensitivity analyses should be conducted to assess the robustness of findings to plausible alternative assumptions about the missing data.
The papers do not include any detail into which variables MICE was used on, details of the specific inputs to MICE or sensitivity analyses that would be required for such extreme results to be plausible.
This is the most charitable case I can come up with to imagine how MICE might explain the results we’re seeing. We'd need an estimation approach that would be, in the best case, indistinguishable from data fabrication, and while not impossible, “multiple imputation” cannot be the magic wand that invalidates any post-hoc analysis of the data. Anomalies as blatant as these require explanation far more detailed than the invocation of the statistical genie.
All that said, I do not actually believe the risk factors specifically were handled with MICE at all. In the fluvoxamine paper, in Table 1, the authors tell us explicitly where they have missing data:

We can see that Race, Age, BMI, Time since onset of symptoms, all specify that some of the data is Unspecified (3%, 6%, 1%, 24% respectively for the placebo group). There is no Unspecified category in risk factors, which I take to mean the authors did not have patients for which they did not know the risk factors, similarly to gender, where they also have complete data. A clinical trial that does not record risk factors for patients appropriately is a clinical trial that is putting patients at unnecessary risk, so the idea that 20% of data would have been missing implies a breach of ethics that is itself quite grave.
Before we move on, some more questions for those who want to continue down the path of using multiple imputation as an explanation for the anomaly:
1. Why is it that papers from the same trial are reported so inconsistently? If imputation was needed for Table 1 in the ivermectin paper, why wasn’t it needed for Table 1 in the fluvoxamine paper? The papers are subject to the same Statistical Analysis Plan. Why does it lead to two different approaches?
2. The trial's Statistical Analysis Plan says that imputation would be used "where statistical models require adjustment for baseline covariates". Which models required asthma or CPD risk to be imputed?
What Other Explanation is There?
Assuming this observation is correct, it is entirely consistent with the hypothesis as laid out in my main article on the TOGETHER trial: the placebo group for the ivermectin trial used patients recruited earlier, and patients coming in during the gamma variant peak were disproportionately allocated to the ivermectin treatment group. If the patients coming in during the peak gamma variant period had different risk factor characteristics than the rest of the patients, that would create a big problem for the authors. Showing the risk factors between ivermectin treatment patients and placebo group patients to be drastically different would be obvious evidence for failure of randomization, which would discredit the trial. So, the hypothesis goes, the authors may have elected to correct the error by falsifying the risk factors of the placebo group.
It is a serious accusation, and I don’t make it lightly, but I have exhausted the possible universe of available hypotheses.
“When you have eliminated all which is impossible, then whatever remains, however improbable, must be the truth.”
~ Arthur Conan Doyle, The Case-Book of Sherlock Holmes
As I wrote in my prior article, the authors can simply elect to release the data to a few neutral investigators (not people who have published with them previously) who can try to provide an explanation for these discrepancies.
So far, not only have they refused to do so, they’ve also stopped responding to emails by people trying to understand what happened. If the data isn’t fabricated, this should be simple to demonstrate. Then we can proceed to try to understand the other discrepancies. The pattern is extremely concerning, both by what is seen in the papers, and in the actions of the trial’s investigators.
This matter is too important to let ego get in the way. Release the data and let science take its course.
Footnotes
From the fluvoxamine paper: "...randomisation to fluvoxamine from Jan 20, 2021 to Aug 5, 2021, when the trial arms were stopped for superiority."
From the ivermectin paper: "The evaluation that is reported here involved patients who had been randomly assigned to receive either ivermectin or placebo between March 23, 2021, and August 6, 2021."
The fluvoxamine paper reports: "756 allocated to and received placebo,'“ the only other placebo mentioned matches the placebo patients allocated to the 2020 HCQ and Lopinavir/Ritonavir studies.
The ivermectin paper mentions "679 were assigned to receive placebo.” All other placebo patients reported were nonconcurrent (375), so while the ivermectin arm was running, all placebo patients recruited were part of its placebo group.
This article is part of a series on the TOGETHER trial. More articles from this series here.
Beginning to look like the COMING-APART trial ...
Is there an explanation as to why the trial data hasn't been made available? Is this propietary data? If there are already papers released discussing the results of the trial, the data should exist in an organized manner no? And if the data backs up the claims made by the authors of the trial wouldn't they release the data without hesitation? I'm just confused because it would seem like releasing the data is the easiest and most convincing way to end controversy surrounding the study