

The TOGETHER Trial Can't Make Up Its Mind About Time-Since-Symptom-Onset
Imputation is being used with no real reason, and it's producing wildly varying results.

This article is part of a series on the TOGETHER trial. More articles from this series here.
Today's post relates to the use of statistical methods in the ivermectin study coming out of the TOGETHER trial. It turns out, what should be the same process, run at different times, produces wildly different results. What’s more, that process should not have been used at all.
Without further ado, let’s dive right in.
The Analysis
In Figure 2 of the paper, we are informed that the two time-since-symptom-onset subgroups consisted of (282+276=) 558 patients for the 0-3 days subgroup, and (242+241=) 483 patients for the 4-7 days subgroup:

Given that the particular study included 1358 patients, we seem to be missing “Time-Since-Symptom-Onset” for 317 patients, or 23% of all patients. This isn’t new, but I thought it was important to establish.
Moving on to Table 1, we see some different numbers:
Time-since-symptom-onset includes (302+295=) 597 patients in the 0-3 days subgroup, and (377+383=) 760 patients in the 4-7 days subgroup. That adds up to 1357 patients, which is very close to the 1358 total.
What’s the difference between the two tables? It’s that little footnote in Table 1: “Missingness in covariate data was handled with multiple imputation by chained equations.”
Without going into too much detail, multiple imputation by chained equations (MICE) is a method for estimating missing values. The Statistical Analysis Plan (SAP) of the TOGETHER trial indeed mentions:
Multiple imputation will be employed where statistical models require adjustment for baseline covariates with up to 20% missing values.
Of course, the same SAP also mentions this:
For categorical variables, summary tabulations of the number and percentage
within each category (with a category for missing data) of the parameter will be presented.
In fact, this is the way it was done in the fluvoxamine paper. There was a clear “Unspecified” category for missing data.
There are a couple of issues here: it’s unclear what statistical model required this adjustment, but even if something existed, we’re missing more than 20% of values, so imputation should not be used according to their own SAP.
But let’s leave all this aside for the moment, because something incredible has been posted on the TOGETHER trial website. If we visit togethertrial.com/publications, we see an interesting link titled “Figure 2 using imputed data.” It looks something like this:
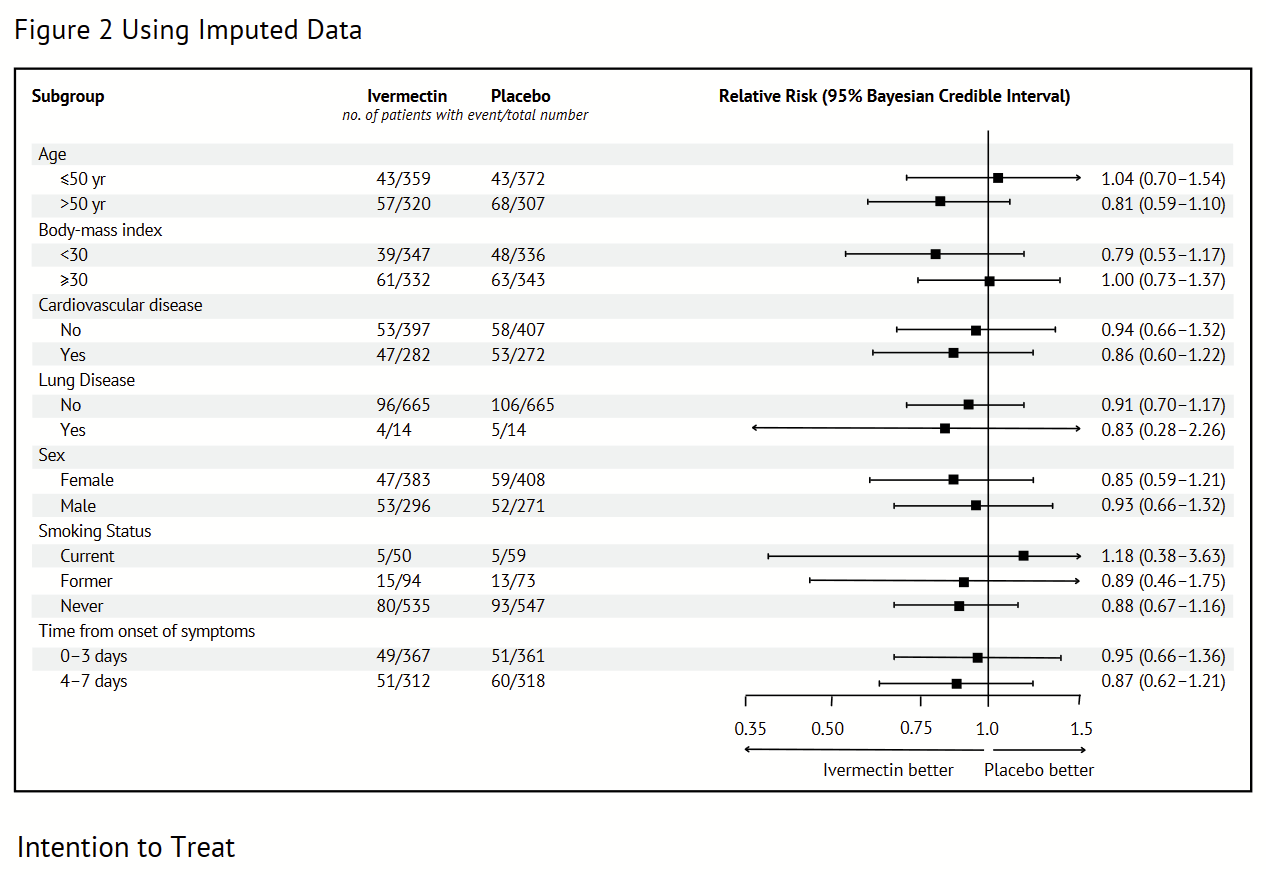
Here’s where things get interesting. If we repeat the analysis on the imputed data, we see that the 0-3 days subgroup is composed of (367+361=) 728 patients, and the 4-7 days subgroup is composed of (312+318=) 630 patients, adding up to 1358, as expected.
So now we have some real questions:
How many patients were in the 0-3 days subgroup? Was it 597 as shown in Table 1? Or was it 728 as shown in “Figure 2 Using Imputed Data?”
And how many patients were in the 4-7 days subgroup? Was it 760 as shown in Table 1? Or was it 630 as shown in “Figure 2 Using Imputed Data?”
All other subgroups are imputed the same way in Table 1 and “Figure 2 Using Imputed Data.” But when it comes to “Time-from-onset of symptoms,” the two results are about as different as can be. We have 261 patients moving from one category to the other. That’s 19.2% of the whole patient population; it’s not a small difference.
This seems to point to some issue in the imputation code used for the two tables, and since both of them are presented as official publications by the TOGETHER trial authors, this is a difference that must be explained (or, most likely, corrected).
Other Time-From-Symptom-Onset Issues
We’ve covered several issues with the time-from-symptom-onset field, and yet, they’re not nearly all of them. Here’s a quick summary of the rest:
1. The 317 missing TFSO patients actually had a highly significant decrease in hospitalization and/or ER observation > 6h. How does this even happen?



2. Time-from-symptom-onset is an inclusion criterion. If it wasn’t known, how did the patients even get included in the trial?
3. In the Statistical Analysis Plan, the time-from-symptom-onset boundary is defined as 96 hours. That would seem to imply that we would have 0-4 days and 5-7 days. Why was the subgroup boundary changed for publication?
4. The paper writes “The mean (±SD) number of days with Covid-19 symptoms before randomization was 3.8±1.9.” However, this must be only within people with known time-from-symptom-onset. Depending on when the remaining patients had symptom onset, that number could be very different.
In Closing
This piece demonstrates that there’s not only uncertainty about the data of the TOGETHER trial, but the code used to do operations like MICE.
Once more, the only solution is for data and code to be released so we can finally know the truth about what happened in this trial. The authors should be made to keep their promise to the academic community and release them so that they can be audited.
This article is part of a series on the TOGETHER trial. More articles from this series here.
Another great article.
I would suspect most trials (Ivermectin or not) if put under the microscope like this would have similar anomalies if you looked hard enough. The big difference here is the headlines this trial made, perhaps even pro-actively generated by the trial authors (or sponsors) themselves.
In such a setting, the trial therefore deserves to be picked apart at the seams.
You mention the better outcomes seen with the subgroup receiving the first dose within three days of symptoms. Couple this with an analysis excluding all those who received less than 400mcg/kg and I think you would almost certainly get a statistically significant result.
Once you get access to the raw data I’d encourage you to do this analysis.
I don’t think they’ll give you the data though, it may very well mean the end of Ed Mills career as a researcher.
Also, I’d presume Ed and the others involved in this trial are reading every word you write (and these comments) and are quietly panicking.
I’m guessing they’re leaving it as long as possible until they release the data so as to formulate a strategy so as to best defend themselves. Sometimes the best form of defence is attack and therefore they maybe be preparing a strategy to take you down...be careful!
Thank you for persisting. I take great interest in this investigation.