This is a public peer review of Scott Alexander’s essay on ivermectin, of which this is the fifth part. You can find an index containing all the articles in this series here.
Similarly to Biber et al., Babalola et al. is another of the studies where Scott follows Gideon Meyerowitz-Katz off a cliff, wrongly placing real doubt on the capability and/or integrity of the researchers, while at the same time omitting exculpatory information. Another case that could probably have been avoided had Scott engaged some counterweight to Gideon’s one-sided criticism.
Let’s walk through what Scott had to say about it:
Babaloba et al:Be warned: if I have to refer to this one in real-life conversation, I will expand out the “et al” and call it “Babalola & Alakoloko”, because that’s really fun to say.
(*The name of the first author is Babalola, not Babaloba. If I’m bitter, it’s only because I spent an inordinate amount of time Googling for a non-existent study. But let’s get back to our regularly scheduled rant.)
This was a Nigerian RCT comparing 21 patients on low-dose ivermectin, 21 patients on high-dose ivermectin, and 20 patients on a combination of lopinavir and ritonavir, a combination antiviral which later studies found not to work for COVID and which might as well be considered a placebo. Primary outcome, as usual, was days until a negative PCR test. High dose ivermectin was 4.65 days, low dose was 6 days, control was 9.15, p = 0.035.
Figure 2 is apparently a photograph of the computer screen where they did this calculation.
So far so good (other than the unnecessary snark about the “photograph of the computer screen”). What follows is the meat of the critique:
Gideon Meyerowitz-Katz, part of the team that detects fraud in ivermectin papers, is not a fan of this one:
So what we have here are two accusations.
The first accusation is that “they’ve clearly got missing data and/or errors in tabulation,” I think. Keep in mind that the “high-quality, well-respected” TOGETHER trial is missing 23% of the “time to symptom onset” data, and more than 7% of the age data for its patients. Both of these are inclusion criteria, by the way, so it’s unclear if these patients should even be in that trial. But somehow the absence of a datapoint is enough to disqualify this study?
The second accusation is that the authors made a “few really bizarre choices,” but I have not seen those documented anywhere, so this accusation is completely unsubstantiated. Back to Scott:
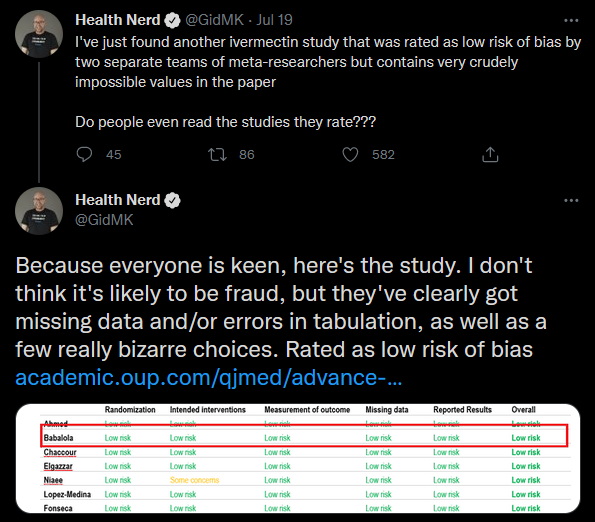
He doesn’t say there what means, but elsewhere he tweets this figure:
It’s always a bad sign when your study features in an image with “NUMEROUS IMPOSSIBLE NUMBERS” in red at the top.
I think his point is that if you have 21 people, it’s impossible to have 50% of them have headache, because that would be 10.5. If 10 people have a headache, it would be 47.6%; if 11, 52%. So something is clearly wrong here. Seems like a relatively minor mistake, and Meyerowitz-Katz stops short of calling fraud, but it’s not a good look.
Talk about making a mountain out of a molehill. Missing data is a common issue in almost every clinical trial. In the comments, a fascinating comment on the original essay by user Aristophanes digs into the supposed “something” that is “clearly wrong.” Here’s the essence of it:
We have four columns - 1 for treatment A, B and control each, plus an overall. This allows us to triangulate to see what has happened with the data.
Column A is the mystery - how do you get 50% of 21 people, and so forth? Easy, have K people who have missing data for this outcome. Happens all the time. (In my research, I deal with much larger samples, but there's always missing values for some trivial % of the data). Technically you can have different numbers of missing by variable, but the easiest solution to make (at least a few) of these numbers work is to allow 1 person with missing data in Column A.
Then we have 6/20 with fever, 10/20 = 50% with headache, and so forth. Columns B and C look fine. Ok, the question then is does my "fix" give the correct totals in the "overall" column? Turns out that (as far as I checked, it does)
Details:
Headache: 10/20 in col A, 12/21 in col B, 5/20 in col C. This would give 27/61 overall, which is 44.26%, which matches their 44.3% exactly.
Fever: 6/20 in col A, 9/21 in col B, 4/20 in col C. This would give 19/61 overall, which is 31.147%. They report 31.2%. This *doesn't quite match*. But if you round to 2 dp, you get 31.15%. And then if someone later rounds to 1 dp, you get (incorrectly) 31.2%. I bet errors like this happen all the time - you have your software print the result to 2 dp, and then as you write your table, you decide to do 1 dp and every time you have something end with "5" you don't go and check which way the raw data should round. (I bet I make this mistake in my research all the time when rounding coefficients and so forth manually in text, because who always remembers to stop and check?).
Haven't checked the other variables, but getting these sufficiently close matches for the first two I checked for the most simple "non-fraud" explanation of "1 data point missing" seems too much of a fluke otherwise.
In other words, a very very simple case of missing data has been made into the reason to reject a study with extremely valuable data. Scott’s verdict:
I’m going to be slightly uncomfortable with this study without rejecting it entirely, and move on.
Interestingly enough, Kyle Sheldrick, another member of “the team that detects fraud in ivermectin papers” actually asked for the data from Prof. Babalola, who provided it to him. Sheldrick, not known for letting positive studies off the hook, to his credit, was unequivocal:
So basically, what we have in this situation is essentially identical to Biber et al.: Scott outsourced his judgement to GidMK, who in turn took a very common occurrence of missing data—which is extremely non-contentious in clinical trials—and turned into an accusation of (at the very least) incompetence.
What’s more, Sheldrick’s analysis was available before Scott wrote his article, yet nobody thought to mention it to him. Or, if Scott knew about it, he chose not to mention it. I suspect the former.
The very clear and exculpatory comment from user Aristophanes was also ignored. I don’t think this is necessarily a “fault” of Scott’s on the first level, but it does leave us with a taste for what could have been. Scott’s audience is extremely sophisticated and contains multitudes of people who could help comb through studies in great depth to see whether the issues raised are legitimate or not. Had Scott put out a call to get his readership to help parse the studies, we might have had a quantum leap in our understanding of the ivermectin literature. Instead, all we got is a superficial reading—channeling GidMK’s biases—which, sadly, gave the readers an illusion of in-depth analysis.
As far as I can tell, Scott discarded a good study here, and besmirched the reputation of the researchers by amplifying flimsy allegations that were known to be off-base at the time that the article was written.
This is a public peer review of Scott Alexander’s essay on ivermectin, of which this is the fifth part. You can find an index containing all the articles in this series here.
To be notified when new articles are released, you can subscribe below:
You have been relentless on this. Which is awesome. Thanks. From afar it really does look like the 'establishment' doth protest too much given what could be a measure people could take where the downside is no worse than say whatever the downside is to masking kindergarteners and their teachers all day. The upside being maybe more people could move on from this epidemic knowing they have one more tool in their belt...even if it is just a placebo effect why begrudge people the psychological boost.
> Had Scott put out a call to get his readership to help parse the studies, we might have had a quantum leap in our understanding of the ivermectin literature.
If nothing else, hopefully Scott finds out about this great idea of crowd-sourcing some of his analyses.

 SARS CoV-2 PCR ASSAY X axis: 1=84hrs, 2=168hrs, 3= 252hrs, 4=336hrs.")



You have been relentless on this. Which is awesome. Thanks. From afar it really does look like the 'establishment' doth protest too much given what could be a measure people could take where the downside is no worse than say whatever the downside is to masking kindergarteners and their teachers all day. The upside being maybe more people could move on from this epidemic knowing they have one more tool in their belt...even if it is just a placebo effect why begrudge people the psychological boost.
> Had Scott put out a call to get his readership to help parse the studies, we might have had a quantum leap in our understanding of the ivermectin literature.
If nothing else, hopefully Scott finds out about this great idea of crowd-sourcing some of his analyses.