This is still just a possibility. Maybe I’m over-focusing too hard on a couple positive results and this will all turn out to be nothing.
That’s interesting, because at the top of this section Scott says “But my answer is: worms!”
Or who knows, maybe ivermectin does work against COVID a little - although it would have to be very little, fading to not at all in temperate worm-free countries.
According to Scott’s own results, we see something like a 29%-55% improvement in outcomes. This is with Scott’s handpicked studies alone. Scott describes this as “maybe ivermectin does work against COVID a little - although it would have to be very little, fading to not at all in temperate worm-free countries.”
Here’s the thing: in the dichotomous analysis Scott published, for high-prevalence countries, ivermectin showed a whopping 75% reduction in mortality. While I have been more than critical of Scott’s analysis and how he got there, if Scott takes it seriously, he must take all its conclusions seriously too, not just the ones that are convenient.
But this theory feels right to me.
Shrug.
It feels right to me because it’s the most troll-ish possible solution. Everybody was wrong!
Go on…
The people who called it a miracle drug against COVID were wrong.
The person Scott (and everyone else) refers to with this is Dr. Pierre Kory, who used a single turn of phrase, that has been turned into a weapon of mass destruction against ivermectin. What did he mean when he said it? Well, what we know is that he always, and I mean always, recommends ivermectin as part of a long and complicated protocol containing many other drugs. So while we might disagree about the meaning of his words, his actions show clearly that he believed ivermectin to be one of a panoply of drugs that can be used to fight COVID-19.
My own suspicion is that he might have been echoing the words of ivermectin’s Nobel-prize winning discoverer, Satoshi Omura. In 2011, he wrote the paper “Ivermectin, ‘Wonder drug’ from Japan: the human use perspective.“ The interpretation that Dr. Kory meant COVID can be defeated with ivermectin alone was always false, and trivially demonstrable to be so.
The people who dismissed all the studies because they F@#king Love Science were wrong.
OK…
Ivmmeta.com was wrong.
Scott’s case against ivmmeta—as we’ve seen—is a house of cards in an earthquake zone during tornado season. However, since both Scott and ivmmeta find a clear benefit from ivermectin, what would Scott’s contention ultimately be?
Gideon Meyerowitz-Katz was…well, he was right, actually, I got the worm-related meta-analysis graphic above from his Twitter timeline.
Except that Gideon Meyerowitz-Katz doesn’t endorse the worms hypothesis—as far as I know—and he was one of the people who “dismissed all the studies because they F@#king Love Science.” Remember, he called ivermectin “something else to debunk” back in 2020. He’s promoted the despicable “horse paste” meme, too.
Also, the best part is that I ignorantly asked, in my description of Mahmud et al above:
And it was! It was a fluke! A literal, physical, fluke! For my whole life, God has been placing terrible puns in my path to irritate me, and this would be the worst one ever! So it hasto be true!
The Scientific Takeaway
About ten years ago, when the replication crisis started, we learned a certain set of tools for examining studies.
Check for selection bias. Distrust “adjusting for confounders.” Check for p-hacking and forking paths. Make teams preregister their analyses. Do forest plots to find publication bias. Stop accepting p-values of 0.049. Wait for replications. Trust reviews and meta-analyses, instead of individual small studies.
So, did Scott do any of these before endorsing the Strongyloides hypothesis?
Check for selection bias: are the populations in Strongyloides high- and low-prevalence countries different in some way that might explain what we see beyond the worms hypothesis? Nobody asked.
Distrust “adjusting for confounders:” no worries about this one—no adjusting for confounders was done whatsoever in investigating the hypothesis.
Check for p-hacking and forking paths: did Scott check the Strongyloides hypothesis for either of these? I’m going to guess no. In fact, he incorporated a second iteration in an update of the analysis that showed stronger results, which I’m sure he’d call p-hacking if someone else did it.
Make teams preregister their analyses: or, you know, don’t mind, unless of course you disagree with the conclusions, in which case, do.
Do forest plots to find publication bias: Scott here means funnel plots, but as with many of the other tools, these are not to be used without careful analysis of context. Much like Carlisle’s methods, they’re a screen, not a filter.
Stop accepting p-values of 0.049: instead, accept p-values of 0.27 like Scott did for the initial version of the Strongyloides hypothesis, or p-values of 0.47 like the meta-regression of the final version of the Strongyloides hypothesis. Yippee.
Wait for replications: unless you’re testing a vaccine, in which case, don’t.
Trust reviews and meta-analyses, instead of individual small studies: I’m literally dying over here folks.
Perhaps the lesson learned—going by revealed preferences—is that those things should be demanded of others, but the smart, clued-in rationalists can just skip them and go with their gut. The glaring lack of self-reflection here is quite something.
These were good tools. Having them was infinitely better than not having them. But even in 2014, I was writing about how many bad studies seemed to slip through the cracks even when we pushed this toolbox to its limits. We needed new tools.
I think the methods that Meyerowitz-Katz, Sheldrake, Heathers, Brown, Lawrence and others brought to the limelight this year are some of the new tools we were waiting for.
Let’s remember who these people are: these are the people who made false claims about dozens of scientists, and framed the absence of released data as a moral flaw. When asked to release the data their claims were based on, they provided nothing.
This exchange was over a year ago:
Scott continues:
Part of this new toolset is to check for fraud.
As we’ve covered a number of times in this series, these tools cannot “check for fraud.” The best they can do is to check for irregularities, which—most of the time—are typos. They do, on occasion, also catch fraud, but the initial assumption upon seeing a positive result from one of these tools cannot justifiably be “this is fraud.”
About 10 - 15% of the seemingly-good studies on ivermectin ended up extremely suspicious for fraud. Elgazzar, Carvallo, Niaee, Cadegiani, Samaha.
Elgazzar is the banner case, so let’s say this one was indeed highly suspect.
Samaha is another one that looks quite dodgy.
Carvallo is one we’ve looked at in detail. I’d say sloppy is warranted, fraud is not, unless Scott feels like throwing TOGETHER into the mix as well. Even so, this trial is not early treatment, but prophylaxis.
Niaee is suspected for randomization failure, not fraud, as far as I know. TO THE DUNGEON!
Cadegiani’s ivermectin study is one where Scott has not substantiated his accusation of fraud in the slightest, so it’s interesting to see it here. I guess we’re going with “I made fun of him enough, who’s going to check?”
We have two cases where the situation is indeed deeply troubling, two that look sloppy but not necessarily fraudulent (one of which is on prophylaxis), and of course Cadegiani gets a kick in the nuts because why not.
If Scott calculated the 10-15% number on the basis of 5/32 = 15.6%, then I’m afraid to say that he’s only made the case for a number somewhere in the single digits.
Health research is based on trust. Health professionals and journal editors reading the results of a clinical trial assume that the trial happened and that the results were honestly reported. But about 20% of the time, said Ben Mol, professor of obstetrics and gynaecology at Monash Health, they would be wrong. As I’ve been concerned about research fraud for 40 years, I wasn’t that surprised as many would be by this figure, but it led me to think that the time may have come to stop assuming that research actually happened and is honestly reported, and assume that the research is fraudulent until there is some evidence to support it having happened and been honestly reported.
If about 20% of trials are expected to be of extremely low quality, and/or fraudulent, all Scott is telling us is that the ivermectin literature is unusually clean, even if we’re going with an extremely expansive definition of “fraud.” But let’s continue:
There are ways to check for this even when you don’t have the raw data. Like:
The Carlisle-Stouffer-Fisher method: Check some large group of comparisons, usually the Table 1 of an RCT where they compare the demographic characteristics of the control and experimental groups, for reasonable p-values. Real data will have p-values all over the map; one in every ten comparisons will have a p-value of 0.1 or less. Fakers seem bad at this and usually give everything a nice safe p-value like 0.8 or 0.9.
GRIM - make sure means are possible given the number of numbers involved. For example, if a paper reports analyzing 10 patients and finding that 27% of them recovered, something has gone wrong. One possible thing that could have gone wrong is that the data are made up. Another possible thing is that they’re not giving the full story about how many patients dropped out when. But something is wrong.
Yep. As we’ve discussed extensively, these methods are far better at catching typos than they are at catching fraud, but, you know, you do you.
But having the raw data is much better, and lets you notice if, for example, there are just ten patients who have been copy-pasted over and over again to make a hundred patients.
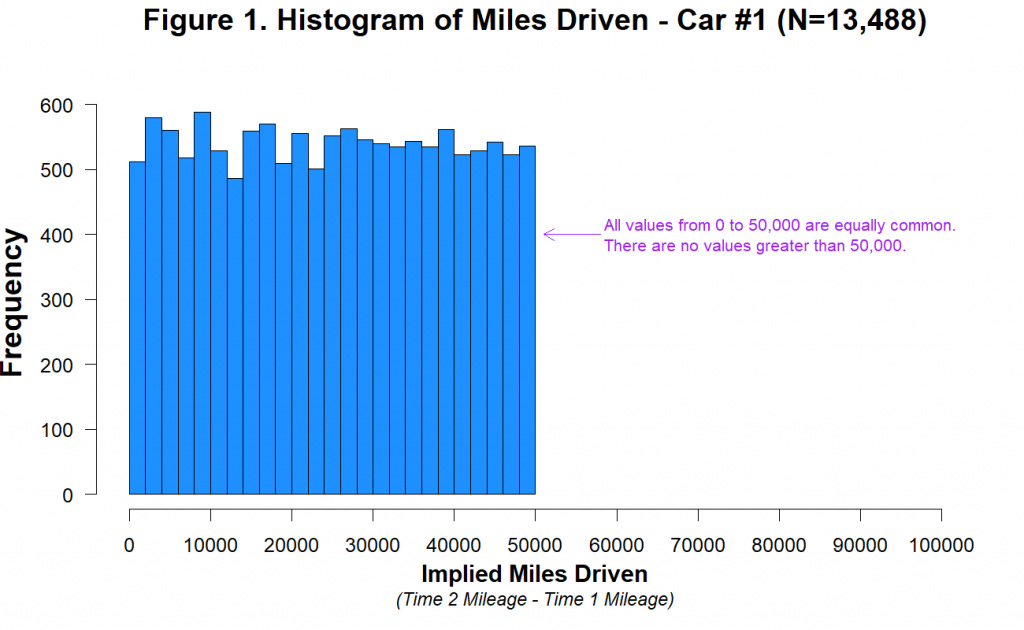
Or if the distribution of values in a certain variable is unrealistic, like the Ariely study where cars drove a number of miles that was perfectly evenly distributed from 0 to 50,000 and then never above 50,000.
Source. Real data would follow something like a bell curve.
This is going to require a social norm of always sharing data. Even better, journals should require the raw data before they publish anything, and should make it available on their website.
Let’s remember that three of the five studies Scott accused of being fraudulent willingly made their data available. In fact, Cadegiani made the data available over the web to anyone who cared to check it—with no permission needed—as Scott encourages here. Given the treatment Scott gave him in this article, I’d say it has been a net negative in terms of encouraging open science. You see, the “social norm of always sharing data” implies a “social norm of not defecting on people who share their data by calling them criminals on a (statistical) whim.”
People are going to fight hard against this, partly because it’s annoying and partly because of (imho exaggerated) patient privacy related concerns. Somebody’s going to try make some kind of gated thing where you have to prove you have a PhD and a “legitimate cause” before you can access the data, and that person should be fought tooth and nail (some of the “data detectives” who figured out the ivermectin study didn’t have advanced degrees). I want a world where “I did a study, but I can’t show you the data” should be taken as seriously as “I determined P = NP, but I can’t show you the proof.”
Get ready to call TOGETHER out, then. I’ll wait. OK, fine, maybe ACTIV-6?
The second reason I think this, aside from checking for fraud, is checking for mistakes. I have no proof this was involved in ivermectin in particular.
Let’s stop and enjoy the inversion here for a second. Scott takes the trouble to say “he has no proof” that the most obvious explanation for his accusations happened, but has no problem calling working researchers “known fraudsters” with nary a caveat in sight.
But I’ve been surprised how often it comes up when I talk to scientists. Someone in their field got a shocking result, everyone looked over the study really hard and couldn’t find any methodological problems, there’s no evidence of fraud, so do you accept it? A lot of times instead I hear people say “I assume they made a coding error”. I believe them, because I have made a bunch of stupid errors. Sometimes you make the errors for me - an early draft of this post of mine stated that there was an strong positive effect of assortative mating on autism, but when I double-checked it was entirely due to some idiot who filled out the survey and claimed to have 99999 autistic children. In this very essay, I almost said that a set of ivermectin studies showed a positive result because I was reading the number for whether two lists were correlated rather than whether a paired-samples t-test on the lists was significant.
Phew! Dodged a bullet there, brother. Those t-tests are super finicky!
I think lots of studies make these kinds of errors. But even if it’s only 1%, these will make up much more than 1% of published studies, and much more than 1% of important ground-breaking published studies, because correct studies can only prove true things, but false studies can prove arbitrarily interesting hypotheses (did you know there was an increase in the suicide rate on days that Donald Trump tweeted?!?) and those are the ones that will get published and become famous.
Wait till you hear the one with the worms…
So if the lesson of the original replication crisis was “read the methodology” and “read the preregistration document”, this year’s lesson is “read the raw data”. Which is a bit more of an ask. Especially since most studies don’t make it available.
And if they did, Scott made sure that practice stops immediately. After all, better be like TOGETHER—promise to share the data but delay into infinity—and have idiots like me jump up and down telling everyone that your results are mutually contradictory, than be preemptively open like Cadegiani, and literally get lambasted for crimes against humanity.
And this is why we can’t have nice things.
OK, this got a little heavy, I promise the next installment will be more constructive.
This is really a fantastic series that needed to be done. For all of his writing talent SA seems to have a deeply imbedded governance module that kicks in as soon as he wanders too far from the herd.
That makes it really frustrating to read his work on verboten topics because he tends to lay out all of the evidence and logic that are ignored or suppressed and then bizarrely and inexplicably veer off course on flimsy pretexts.







This is really a fantastic series that needed to be done. For all of his writing talent SA seems to have a deeply imbedded governance module that kicks in as soon as he wanders too far from the herd.
That makes it really frustrating to read his work on verboten topics because he tends to lay out all of the evidence and logic that are ignored or suppressed and then bizarrely and inexplicably veer off course on flimsy pretexts.
This has been, and continues, to be the most lucid and productive early treatment review for Ivermectin on the web. Thank you so much. Keep'em coming!