Let's Have a Data Adventure TOGETHER!

Sometimes I wonder if—given the volume of data we have from the TOGETHER trial—we’ll perhaps end up reconstructing the parts of the raw dataset that matter without any official help. Could it be that the information already out there—when we get rid of the various distortions that lead to impossible numbers—constrains the possible datasets in ways that leave only one or very few options? Think of it, perhaps, as a 5000x5000 Sudoku game.
Well, we’re not there yet, but today I wanted to document a fun adventure I went through to get just one more little clue that might amount to something—or to nothing at all.
A few months ago, I became aware of another crumb of information, in a reply published in The Lancet by the principal investigators of the TOGETHER trial to comments by other academics:

There are all sorts of things to say about the introductory text, but I’ll refrain. The last sentence is what I want to focus on, and here I won’t resist a little aside.
The authors claim that due to confusion by regulators, they are willing to offer an alternative view into the main endpoint of the fluvoxamine trial, one that claims is “the same composite endpoint used in the paxlovid and molnupiravir trial(s).” This endpoint is “hospitalization or emergency care > 24h.”
The only slight problem is that this isn’t the primary endpoint of the paxlovid trial (I assume they’re referring to the EPIC-HR trial that supported the drug’s approval). Here’s what it actually was:

The one on molnupiravir is closer, but still not the same:

(To start a parenthesis within a parenthesis, this is how pharma does its gold-standard business when it actually cares to get a drug approved. Note how they say that they will use “modified-intention-to-treat” patients? Well, it turns out, they didn’t declare this in their clinicaltrials.gov entry:

In fact, they don’t even give us the other analyses so we can see whether they’re playing dirty by picking the analysis they want. I think at this point, we have to assume that they did exactly that until proven otherwise. Note that in the TOGETHER trial, the modified-intention-to-treat (mITT) analysis is the one in which ivermectin did best—if only by a little—but was not the result that was put forward by the investigators. End of parenthesis.)
So when we get the mITT qualifier out of the way, we still don’t know if the molnupiravir trial, at least, had the same endpoint as the one the TOGETHER authors are describing. You see, what they write is ambiguous.
When they write:
“Hospitalization or emergency care > 24h”
It could mean—Option 1:
“(Hospitalization or emergency care) > 24h”
Or it could mean—Option 2:
“Hospitalization or (emergency care > 24h)”
Option 1 is more similar to the molnupiravir endpoint, but option 2 is more similar to the TOGETHER endpoint, which was “hospitalization (or emergency care > 6h).”
Oh well. Let’s park that question for now, but it should act as a great example of the infuriating amount of imprecise and/or ambiguous claims that the authors of TOGETHER insert everywhere.
I Was Told There Would Be Data?
Ah, yes. The authors say that “our effect size does not change importantly (relative risk [RR] 0·74 [95% CI 0·56–0·98].”
Is “importantly” a technical term? According to whom? In any case, I decided to check what the difference actually was.
The paper gives us these numbers:

But it says very clearly that it’s giving us BCI, which it defines as “Bayesian credible interval.” In other words, even though the two numbers came from the same trial, they would not be readily comparable.
Imagine my surprise when I tried to compute the conventional 95% CI—so I could compare it with what they gave in the reply in the Lancet—and got the exact same thing:
[RR] 0·68 [95% CI 0·52–0·88]
This means that either the risk ratio interval is identical in Bayesian and non-Bayesian terms—which I find hard to believe—or they put in the non-Bayesian value, despite flagging it as Bayesian. Given that I don’t have a way to compute the 95% BCI Relative Risk Interval, I guess this question will have to wait, because we now have two things to compare:
Hospitalization or (emergency care > 6h): [RR] 0·68 [95% CI 0·52–0·88]
Hospitalization or emergency care > 24h: [RR] 0·74 [95% CI 0·56–0·98]
The paper even gives us the pure hospitalization (for COVID-19) risk ratio interval:
Hospitalization for COVID-19: [RR] 0·79 [95% CI 0·59–1·05]
You’ll note that I’ve marked this [RR] indicating that it is a risk ratio. And surely, since you’re all experts in the ins and outs of the TOGETHER papers, you must be concerned, since the table where this figure is clearly marks it as an “Unadjusted odds ratio.” Now, I might not know what an unadjusted odds ratio is, but I basically recalculated it as a risk ratio based on the event and patient counts the paper provides, and the result is exactly the same.
Now, I hear what you’re saying: is “hospitalization” in the other two endpoints “for COVID-19” or not?
The text from the fluvoxamine paper says this:
Our primary outcome was a composite endpoint of hospitalisation defined as either retention in a COVID-19 emergency setting or transfer to tertiary hospital due to COVID-19 up to 28 days post-random assignment on the basis of intention to treat.
I think that means “hospitalization… due to COVID-19.”
I Was TOLD There Would Be DATA, Alex!
OK OK, fine. I’m getting there. With this setup, I suspect can find out how many patients were observed for over 6 hours but less than 24 hours in an ER context.
Let’s check out our haul one more time:
(1) Hospitalization or (emergency care > 6h): [RR] 0·68 [95% CI 0·52–0·88]
(2) Hospitalization or emergency care > 24h: [RR] 0·74 [95% CI 0·56–0·98]
(3) Hospitalization: [RR] 0·79 [95% CI 0·59–1·05]
(All the above “for COVID-19,” AFAICT)
For the first and third results, we have actual numbers from the published paper:
Hospitalization or (emergency care > 6h):
Treatment: 79 events/741 patients
Placebo: 119 events/756 patients
Hospitalization:
Treatment: 77 events/741 patients
Placebo: 106 events/756 patients
So the numbers we want for “hospitalization or emergency care > 24h” are somewhere in between these two, given that the interval is also between those two.
I plugged the midpoint numbers into my favorite online calculator, and after a bit of up/down fiddling, I have something of a solution:
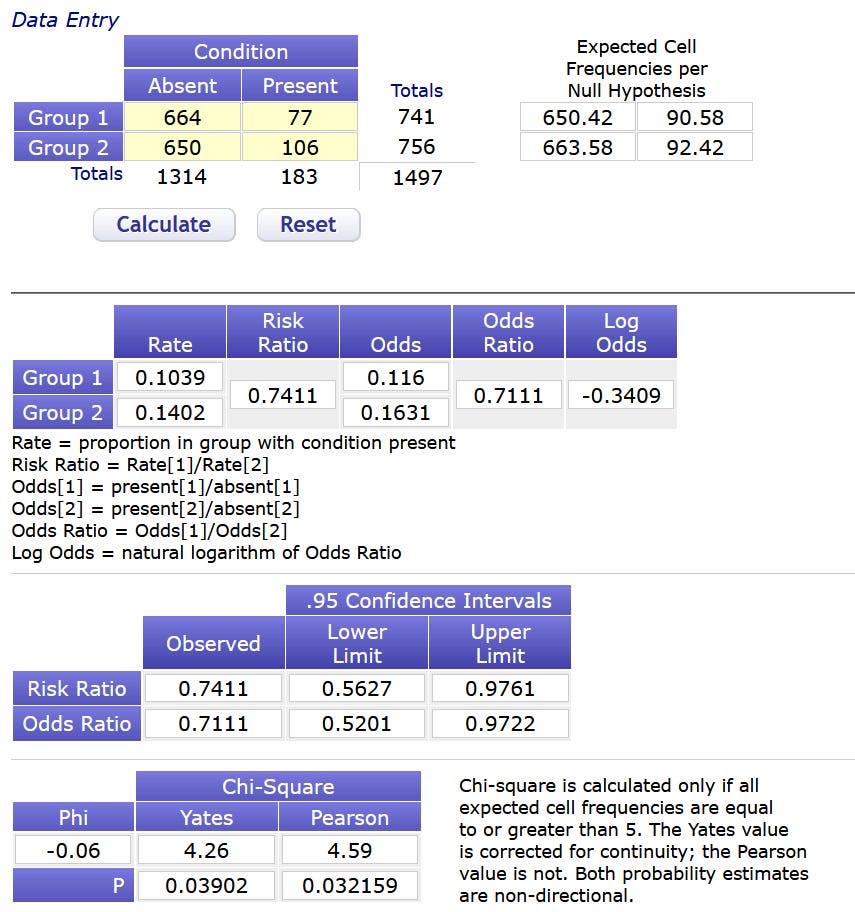
Assuming you can’t read this eyesore the solution is:
Hospitalization or emergency care > 24h:
Treatment: 75 events/741 patients
Placebo: 97 events/756 patients
Is it unique? For complicated reasons, I think so. But if you have reason to think otherwise, or if you find another solution, let me know.
Now, there’s something else that’s interesting there at the bottom:
The p-value for this result is 0.032.
What was the p-value of the original endpoint? It was… (drumroll)… 0.004.
Now, if we are being super fair, the authors did say that they used the same endpoint as molnupiravir. The molnupiravir trial uses the mITT population, not ITT.
So what happens when we adjust these results for mITT?
It seems that one treatment patient and four placebo patients—all of whom had an “event”—were removed from the mITT analysis. So let’s remove them from this analysis also, making only the slightest of assumptions that these are not the patients with the sub-24h ER visits we already removed.
Hospitalization or emergency care > 24h, mITT: [RR] 0·76 [95% CI 0·58–1·01]
p-value: 0.53
Ah, I see. If we try to actually replicate the molnupiravir endpoint, the endpoint most likely loses statistical significance. Or as Ed Mills would say “no evidence of a clinically relevant effect whatsoever.”
So, even though the authors say it changed “not importantly,” I’d say it changed “quite importantly,” seeing as it went from “quite significant” to “meh.”
…and we still don’t know if they meant “(hospitalization or emergency care) > 24h” or “hospitalization or (emergency care > 24h).”
Sometimes I dive in to figure out a little detail that just doesn’t sit right, and I come out having realized that…
![Image - 34041] | The Cake Is a Lie | Know Your Meme](https://substackcdn.com/image/fetch/$s_!nBhB!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fbucketeer-e05bbc84-baa3-437e-9518-adb32be77984.s3.amazonaws.com%2Fpublic%2Fimages%2F724ea761-861b-44cf-a987-eaf0866f4cbf_600x600.jpeg "Image - 34041] | The Cake Is a Lie | Know Your Meme")
When I was still in academia some 10 years ago, and when asked to review papers, I would unwaveringly not recommend publication, for any work that did not intend to publish both code and data that would reproduce all claims and figures; preferably in a single click, not some hastily zipped up folder of incomprehensible spaghetti. I thought the time was kinda right for that; even though boomer editors of journals charging like $40 per view would think that the complexity of hosting a few 100mb was somehow an insurmountable problem. There used to be some genuinely hard problems, like how to get others to actually compile your legacy fortran dependencies. But then docker came along and distributing those kind of dependencies also was sort of a solved problem, if you knew what you were doing.
Id like to think I put my drop in the bucket. But seeing posts like this, in the year 2022, talking about 'the trial of the year', perhaps 'a drop in the desert' would be less presumptuous.
“our effect size does not change importantly (relative risk [RR] 0·74 [95% CI 0·56–0·98].”
#GoldStandard